解決痛點
本技術主要解決AI模型訓練資料標記錯誤問題,其核心痛點包括:
1. 人工標記成本高且容易出錯,尤其在製造業(如瑕疵檢測、設備異常)需專家標記,成本極高;即使重新標記,仍可能持續出現錯誤。
2. 錯誤標記資料會嚴重影響AI模型效能,導致模型學習錯誤,降低預測準確率與穩定性
3. 現有方法假設「一次重標就正確」不符合實務,忽略人為判斷的不確定性與誤差累積
本技術提供的價值:
1. 透過類工業品管概念進行多輪標記資料檢測
2. 將「資料標記」轉為可迭代優化的流程
3. 在有限標記成本下最大化資料品質
4. 同時支援:類別資料與數值資料
技術簡介
本技術為一套AI資料品質優化框架,核心流程如下:
1. 不確定性抽樣,找出可能錯誤標記資料(高風險樣本)
2. 低噪音資料訓練模型,使用可信資料建立穩定模型
3. 高錯誤樣本檢測,由模型辨識疑似錯誤標籤
4. 多次重標與歷史記錄,每筆資料保留多次標記結果
5. 統計聚合修正,類別資料採多數決,數值資料採平均法
技術特點:
1. 可在有限標記預算 B 下最佳化資料品質
2. 模型導向(model-guided inspection)
3. 可與現有模型整合(如 XGBoost)
適用於:
製造品質檢測、影像辨識、IoT異常偵測、金融資料建模
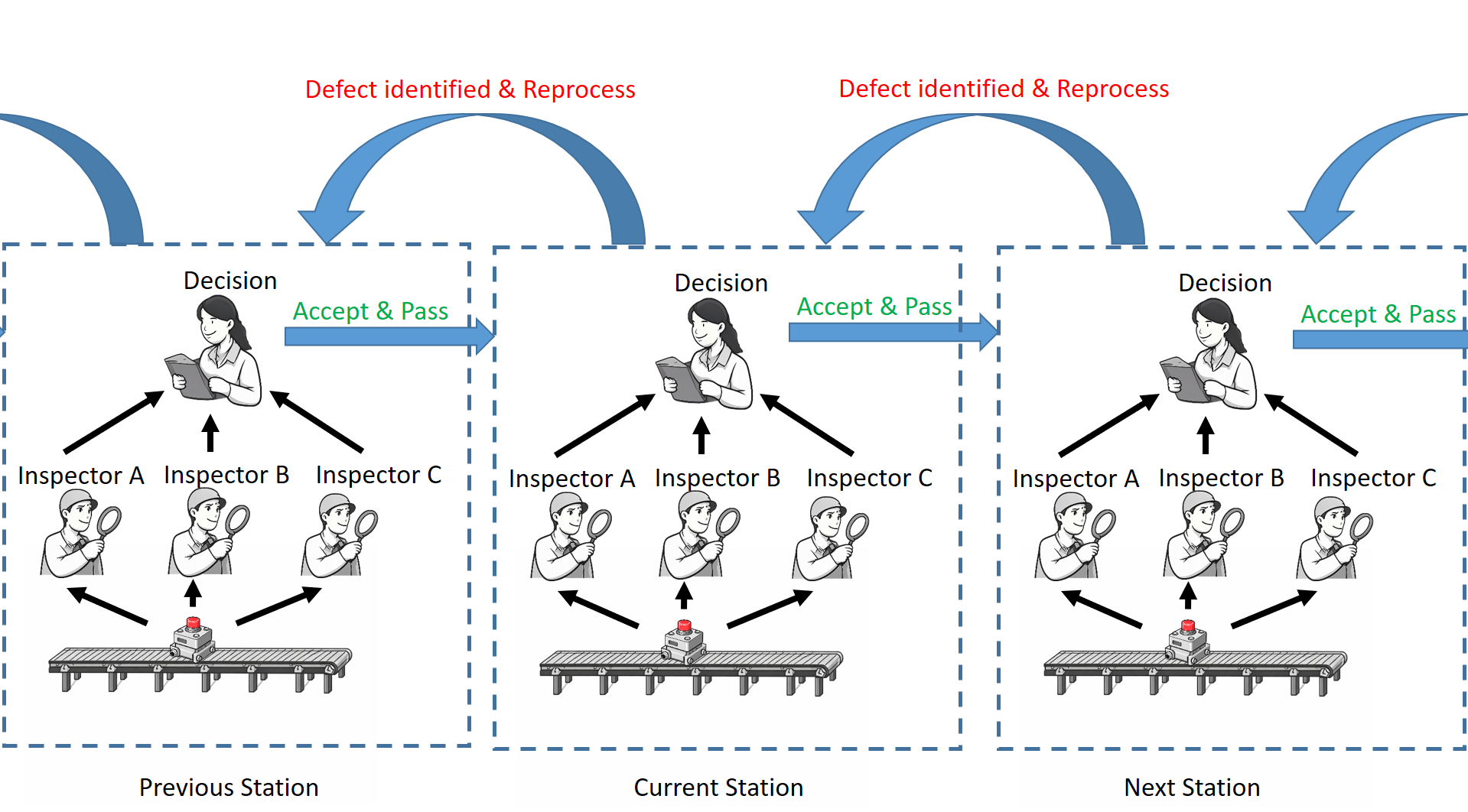
▲圖1:工業品質檢測流程對應AI標記資料修正機制
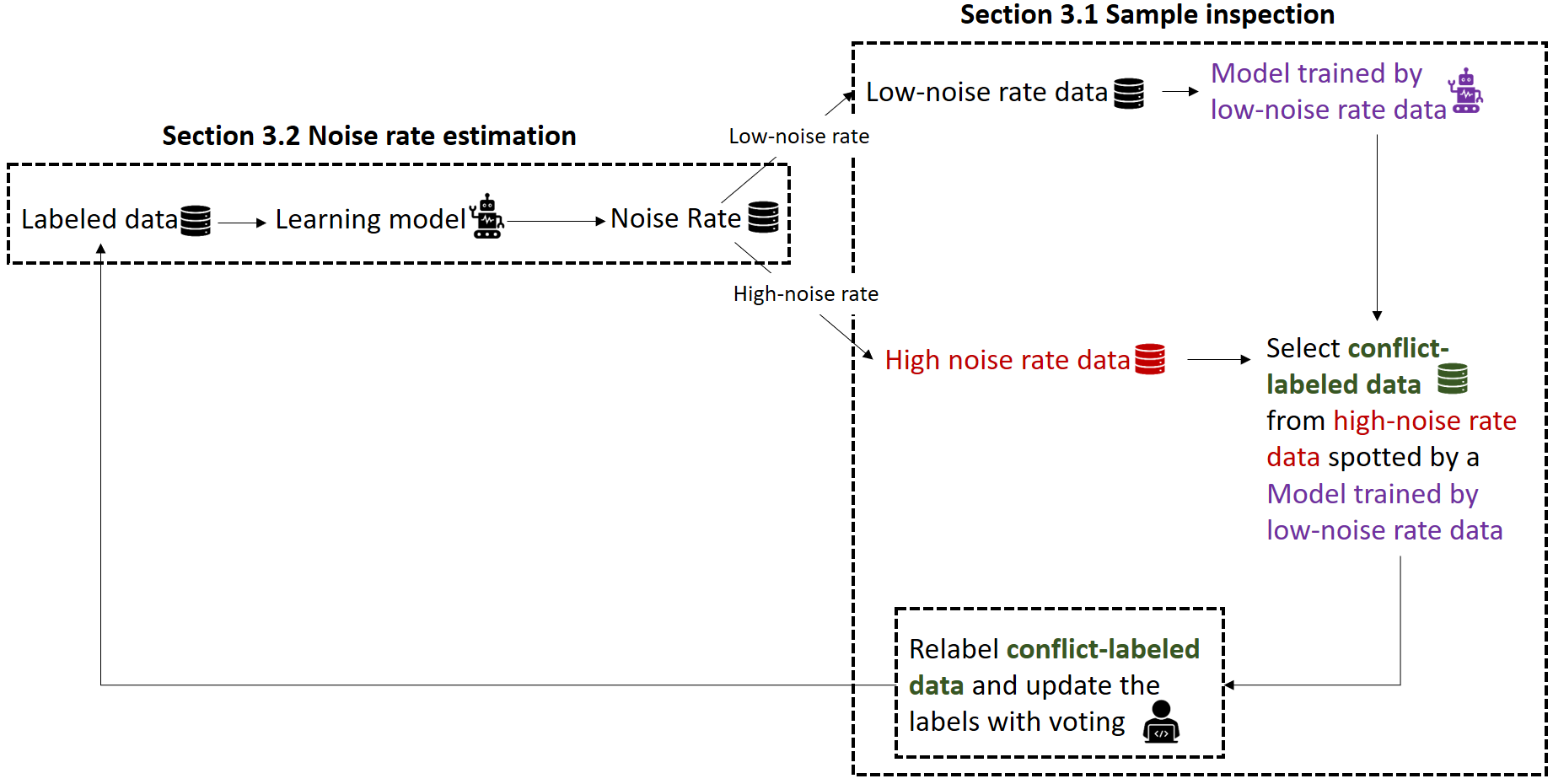
▲圖2:基於不確定性抽樣之標記資料修正架構
應用案例
本技術可應用於智慧製造場域中的設備震動訊號分析與異常偵測系統。在實務中,震動資料常需透過人工或半自動方式進行標記(如正常/異常狀態),但由於訊號複雜且判斷具主觀性,標記資料容易存在錯誤,進而影響模型訓練效果與預測準確度。
本技術透過「抽樣檢查」與多次重標機制,能夠有效識別並修正錯誤標記,建立更高品質的訓練資料集,使震動異常偵測模型能在較低噪音干擾下學習關鍵特徵,進而顯著提升異常辨識的穩定性與準確率。
在此基礎上,經過資料品質優化後的模型亦可進一步延伸應用於設備壽命預測等數值預測任務。由於回歸模型對資料品質更為敏感,本技術所提供的「連續數值標記資料修正機制」可有效降低標記誤差對預測結果的影響,使壽命預測模型更具可靠性與實務應用價值。
綜合而言,本技術可從源頭提升資料品質,串聯「異常偵測」與「壽命預測」兩大核心應用,形成完整的智慧製造設備健康管理解決方案。
相關連結
無
技術產學合作或技轉單位
產學合作單位:譜威科技顧問股份有限公司
獲獎紀錄
無
技術聯絡人
國立中山大學 前瞻產業聯絡中心
連絡電話:07-5250165
聯絡信箱:gloria@mail.nsysu.edu.tw